文章资讯
医疗领域基准测试超越Llama 3、接近GPT-4,上海交大团队发布多语言医学大模型,覆盖6国语言
随着医疗信息化的普及,医疗数据从规模到质量都实现了不同程度的提升。进入大模型时代以来,面向精准医疗、诊断辅助、医患交互等不同场景的各类大模型层出不穷。
但值得注意的是,正如通用模型所面临的多语言能力滞后问题一样,医疗大模型大多依赖于英语的基座模型,同时也受限于多语言医疗专业数据的匮乏、分散,导致模型在处理非英语任务时的表现欠佳。即便是医疗相关的开源文本数据,也主要以高资源语种为主,所支持的语种十分有限。
从模型训练的角度来看,多语言医疗模型能够更加全面地利用全球的数据资源,甚至是扩展到多模态训练数据,从而提升模型对其他模态信息的表征质量。从应用的层面来讲,多语言医疗模型能够帮助缓解医患之间的语言沟通障碍,在医患交互、远程诊断等多场景下,提升诊疗的准确性。
尽管目前的闭源模型展现出了很强的多语言性能,但当下开源领域仍存在多语言医疗模型匮乏的问题,上海交通大学王延峰教授与谢伟迪教授团队创建了一个包含 255 亿 tokens 的多语言医疗语料库 MMedC,开发了一个覆盖 6 种语言的多语言医疗问答评测标准 MMedBench,同时还构建了一个 8B 的基座模型 MMed-Llama 3,在多项基准测试中超越了现有的开源模型,更加适配医疗应用场景。
相关研究成果以「Towards building multilingual language model for medicine」为题,发表于 Nature Communications。
值得一提的是,HyperAI超神经官网的教程版块现已上线「一键部署 MMed-Llama-3-8B」,感兴趣的读者可以访问以下地址,快速上手体验 ↓,我们还在文末为大家准备了详细分步教程!
研究亮点:
* MMedC 是首个专门针对多语言医学领域构建的语料库,同时也是迄今为止最广泛的多语言医学语料库
* 在 MMedC 上的自回归训练有助于提升模型性能,在全面微调评估下,MMed-Llama 3 的性能为 67.75,而 Llama 3 为 62.79
* MMed-Llama 3 在英文基准测试中表现出了最先进的性能,显著超过了 GPT-3.5

多语言医学语料库 MMedC:255 亿 tokens,覆盖 6 种主要语言
研究人员创建的多语言医学语料库 MMedC (Multilingual Medical Corpus),覆盖了英语、中文、日语、法语、俄语和西班牙语这 6 类语种,其中英语所占比例最大,为 42%,中文占比约为 19%,而俄语所占比例最小,仅为 7%。
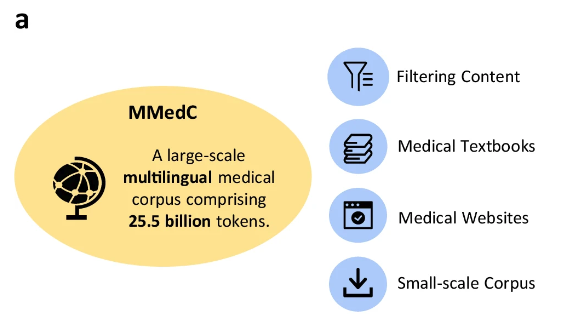
MMedC 包含 255 亿 tokens,从 4 个数据源收集
具体而言,研究人员从 4 个不同的来源收集了 255 亿与医学相关的 tokens。
首先,研究人员设计了一个自动管道,从广泛的多语言语料库中过滤医学相关内容;其次,团队收集了大量不同语言的医学教科书,并通过光学字符识别 (OCR)、启发式数据过滤 (heuristic data filtering) 等方法将其转换为文本;第三,为了保证医学知识的广泛性,研究人员搜集了多个国家开源医学网站上的文本,以权威和全面的医学信息丰富语料库;最后,研究人员整合了现有的小型医学语料库,进一步增强了 MMedC 的广度和深度。
研究人员表示,MMedC 是首个专门针对多语言医学领域构建的预训练语料库,同时也是迄今为止最广泛的多语言医学语料库。
多语言医学问答基准 MMedBench:包含超 5 万对医学多项选择问答
为了更好地评估多语言医学模型的性能,研究人员进一步提出了多语言医学问答基准 MMedBench (multilingual medical Question and Answering Benchmark),汇总了 MMedC 所覆盖的 6 种语言现有的医学多项选择问答题,并利用 GPT-4 为 QA 数据增加了归因分析的部分。
最终,MMedBench 包含 53,566 对 QA,跨越了 21 个医学领域,例如内科、生物化学、药理学和精神病学等。研究人员将其划分为 45,048 对训练样本和 8,518 对测试样本。同时,为了进一步检验模型的推理能力,研究人员选择了一个由 1,136 对 QA 组成的子集,每对都附带经过人工验证的推理语句,作为更专业的推理评估基准。
值得注意的是,答案中包含的推理部分平均由 200 个 tokens 组成,这一较大的标记数量一方面有助于训练语言模型,使其接触到了较长的推理过程;另一方面能够评估模型生成和理解冗长、复杂推理的能力。
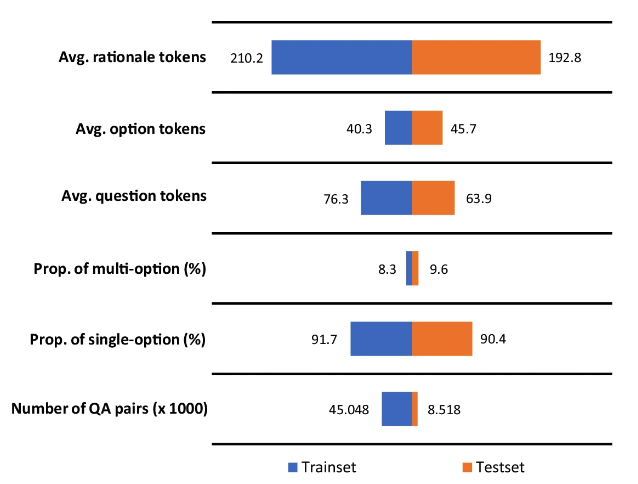
MMedBench 训练集与测试集的基础数值统计信息
多语言医学大模型 MMed-Llama 3:小而美,超越 Llama 3、接近 GPT-4
研究人员基于 MMedC 进一步训练了锚定医学领域知识的多语言模型,分别是 MMedLM(基于 InternLM)、MMedLM 2(基于 InternLM 2)和 MMed-Llama 3(基于 Llama 3)。随后,研究人员在 MMedBench 基准上对模型性能进行了评估。
首先,在多语言多选题与回答任务中,面向医疗领域的大模型往往在英语中表现出较高准确率,但在其他语种下却存在性能下降,这一现象在 MMedC 上的自回归训练后所有改善。例如,在全面微调评估下,MMed-Llama 3 的性能为 67.75,而 Llama 3 为 62.79。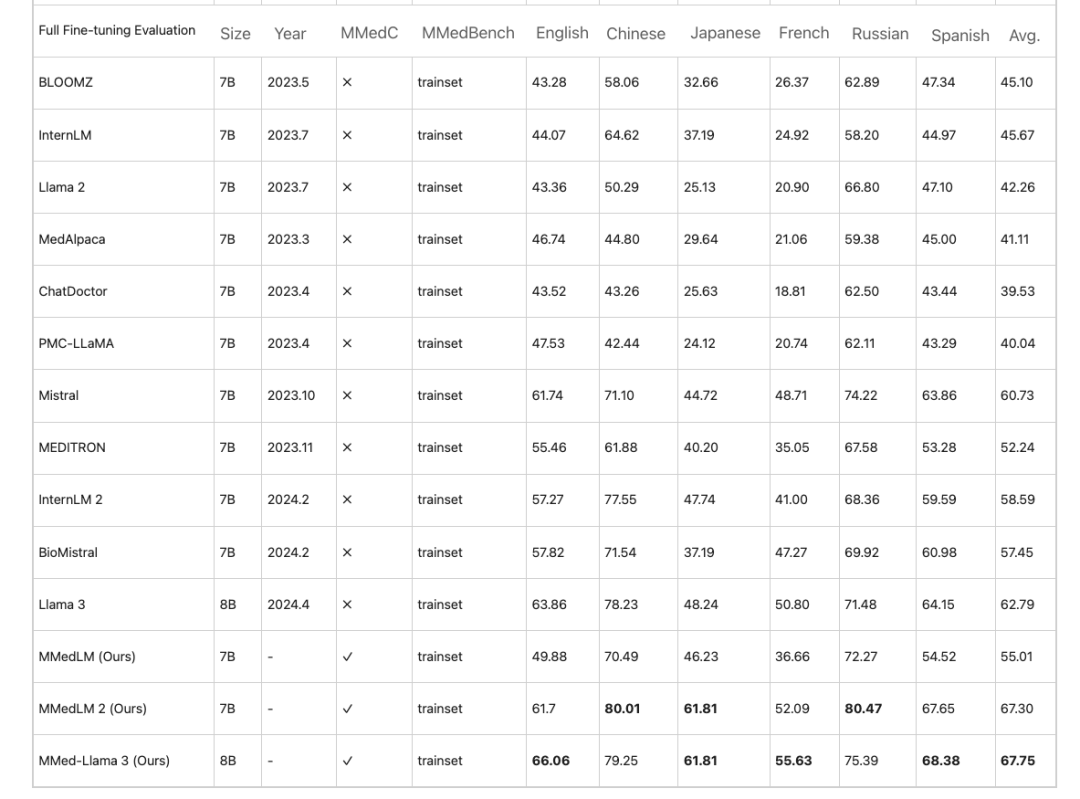
在全面微调评估下,在 MMedBench 上进行的多项选择准确性评估
类似的观察结果也适用于 PEFT(参数高效微调)设置,即 LLMs 后期表现更好,而在 MMedC 上的训练会带来显著的增益。因此,MMed-Llama 3 是极具竞争力的开源模型,其 8B 参数接近 GPT-4 的 74.27 精确度。
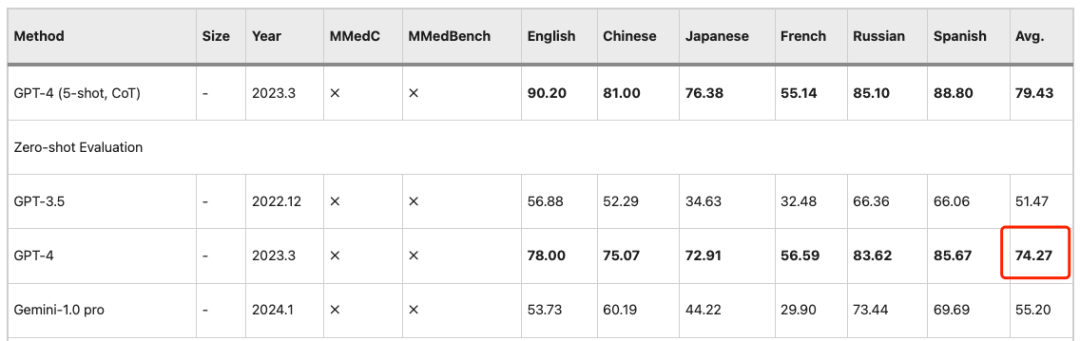
Zero-shot 评估下,GPT-4 的多项选择准确性平均值为 74.27
此外,该研究还组建了一个五人评审组,进一步对模型生成的答案解释进行了人工评估,评审组的成员来自上海交通大学及北京协和医学院。
值得注意的是,MMed-Llama 3 在人工评估和 GPT-4 评估中均获得了最高分,尤其是在 GPT-4 评级中的表现,更是明显优于其他模型,比排名第二的模型 InternLM 2 高出 0.89 分。
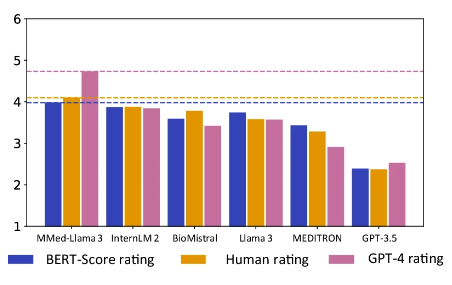
分数条代表不同指标下的排名分数
橘色为人工评估得分,粉色为 GPT-4 评分
为了在英语基准测试上与现有的大型语言模型进行公平比较,研究人员还对 MMed-Llama 3 进行英文指令微调,并在 4 个常用的医疗多项选择问答基准上进行了评估测试,分别是 MedQA、MedMCQA、PubMedQA 和 MMLU-Medical。
结果显示,MMed-Llama 3 在英文基准测试中表现出了最先进的性能,在 MedQA、MedMCQA 和 PubMedQA 上分别获得了 4.5%、4.3% 和 2.2% 的性能增益。同样,在 MMLU 上,其甚至远远超过了 GPT-3.5,具体数据如下图所示。
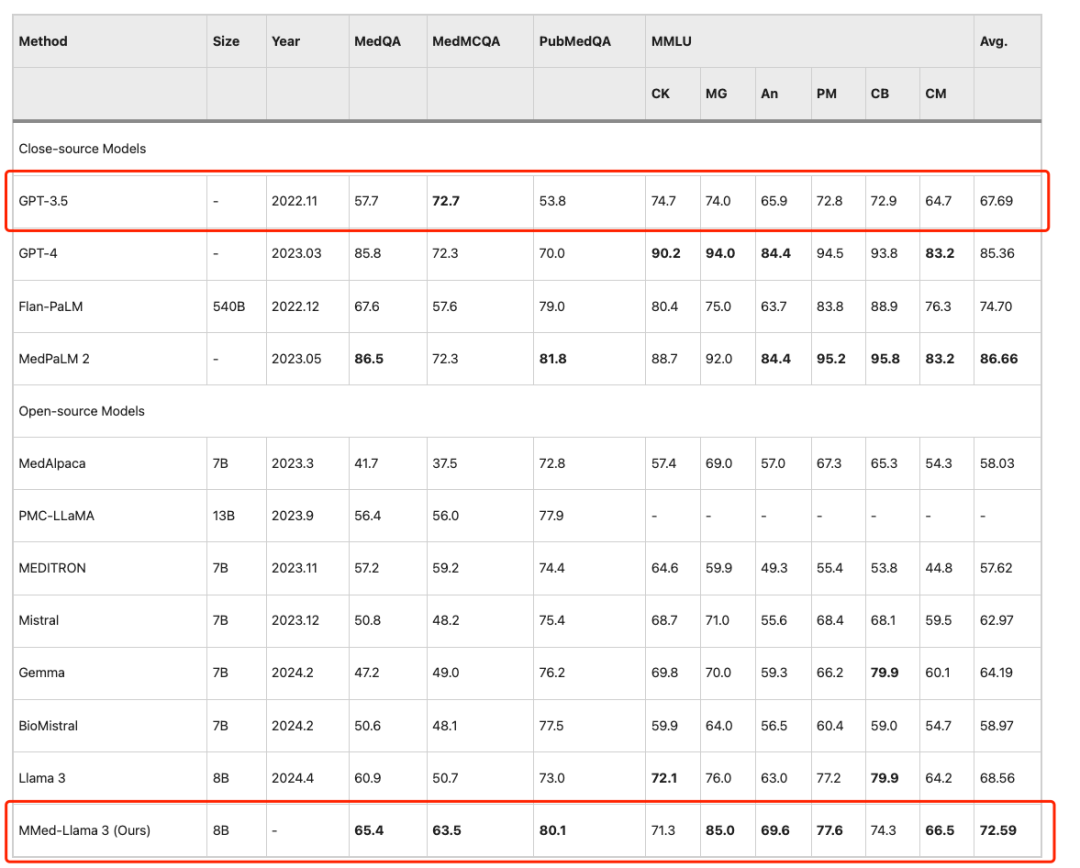
模型在英语基准测试上的评估
一键部署 MMed-Llama 3:突破语言障碍,准确回答常识性医疗问题
如今,大模型已经在医疗影像分析、个性化治疗、患者服务等多个细分场景中实现了成熟应用。聚焦患者的使用场景,面对挂号难、诊断周期长等实际问题,加之医疗模型的准确率持续提升,越来越多的患者会在身体出现轻微不适时,寻求「大模型医生」的帮助,只需要清晰、明确地输入症状,模型便能够提供相应的就医指导。而王延峰教授与谢伟迪教授团队所提出的 MMed-Llama 3 更是通过海量、优质的医疗语料库,进一步丰富了模型的医疗知识,同时还突破了语言障碍,支持多语言问答。
HyperAI超神经的教程版块现已上线「一键部署 MMed-Llama 3」,以下是详细分步教程,手把手教你创建自己的「AI 家庭医生」。
Demo 运行
1. 登录 hyper.ai,在「教程」页面,选择「一键部署 MMed-Llama-3-8B」,点击「在线运行此教程」。
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
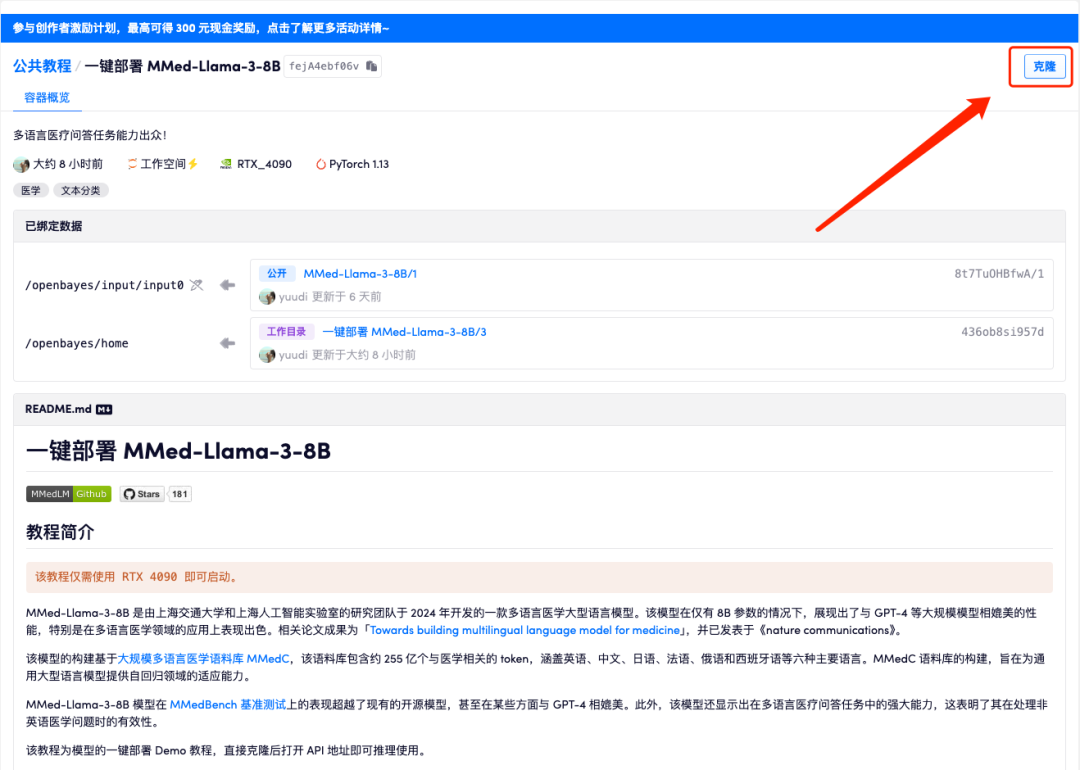
3. 点击右下角「下一步:选择算力」。
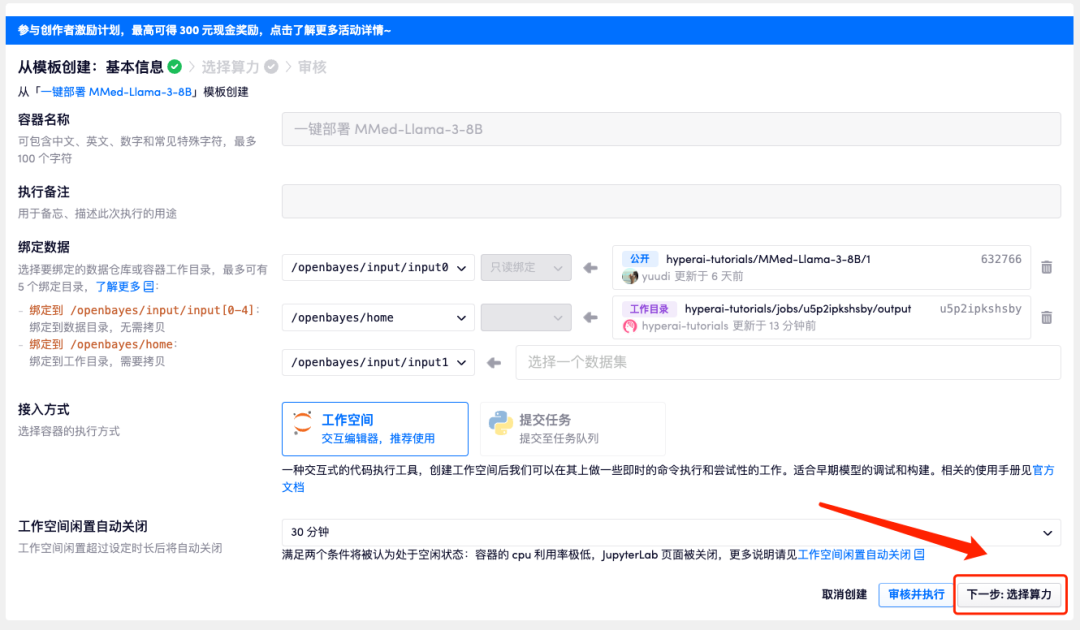
4. 页面跳转后,选择「NVIDIA GeForce RTX 4090」以及 「PyTorch」镜像,点击「下一步:审核」。
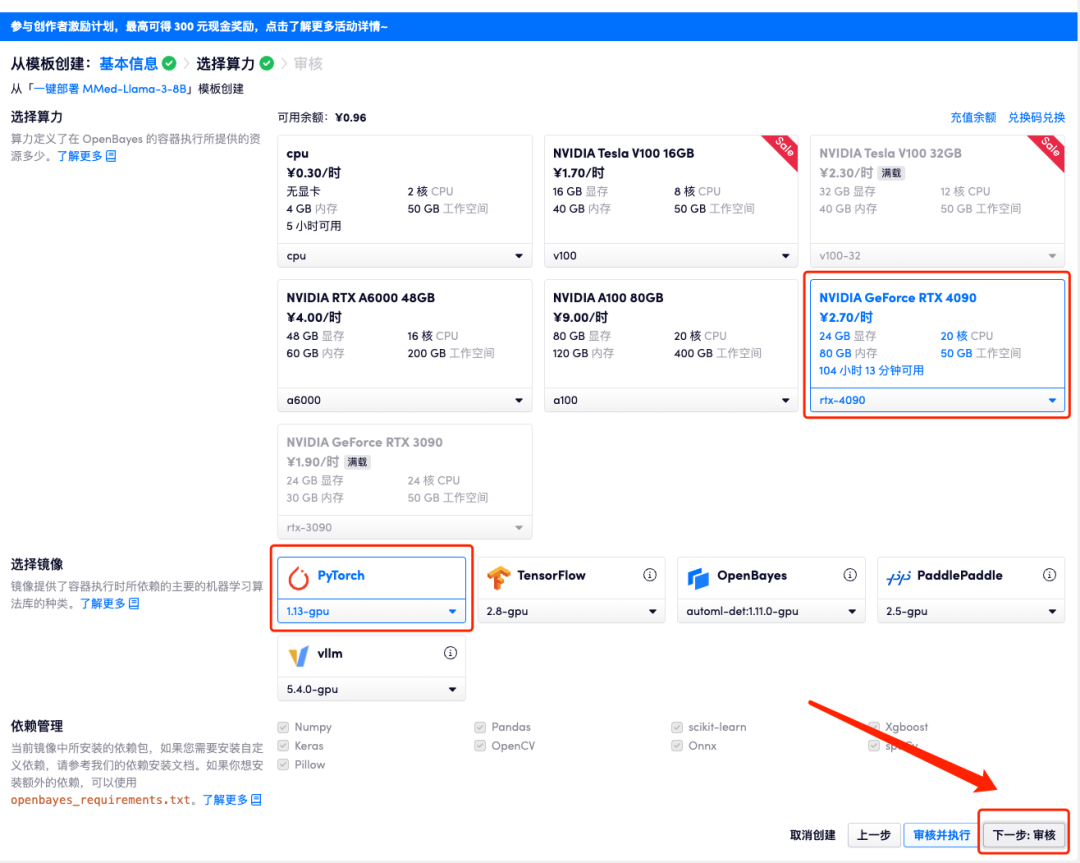
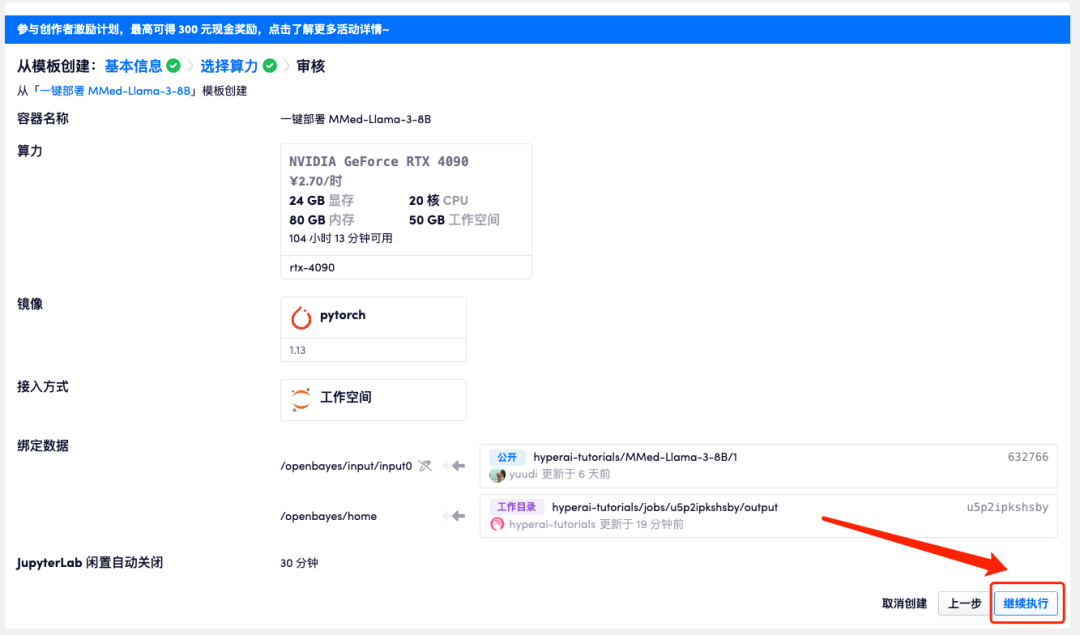
5. 确认无误后,点击「继续执行」,等待分配资源,首次克隆需等待 3 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」边上的跳转箭头,即可跳转至 Demo 页面。请注意,用户需在实名认证后才能使用 API 地址访问功能。
因模型过大,容器显示运行中后,需要稍微等待 1 分钟左右的时间再打开 API 地址,否则会显示 BadGateway。
效果展示
打开 Demo 界面后,我们可以将直接描述症状,并点击提交。如下图所示,当询问「嗓子疼、打喷嚏」的症状是否是感冒时,模型会先介绍感冒的常见症状,并根据自述症状提供诊断。值得关注的是,模型也会提醒用户,「回答无法代替专业医生的资讯或诊疗」。
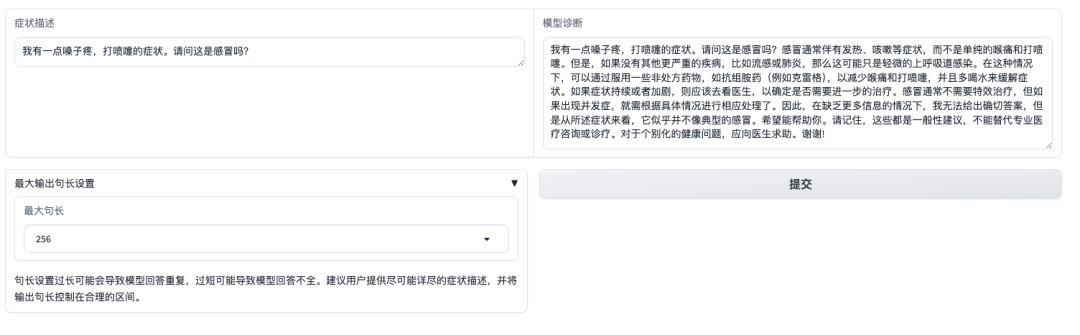
但需要注意的是,不同于商用模型经过了严格的指令微调、偏好对齐、安全控制,MMed-Llama 3 更多是一个基座模型,更加适合结合下游任务数据进行任务特异的微调,而非直接进行零样本问诊,使用时请务必注意模型的使用边界避免相关的直接临床使用。

- 上一篇

上半年仅售590台!捷尼赛思高管表态:不会退出中国市场
今日科普10月24日消息,在昨晚的捷尼赛思GV70上市发布会上,有媒体针对捷尼赛思是否会倒闭的消息进行了提问。对此,捷尼赛思中国CEO朱江明确回应:捷尼赛思会从过去几年的经营当中汲取经验和教训。但更重要的,我们会继续深耕中国市场,不会退出中国市场,反之,我们会知耻而后勇,重整旗鼓。据了解,捷尼赛思在中国市场的销量表现不佳。2023年全年销量仅为1558辆,而2024年上半年仅售出590辆。市
- 下一篇

忍者蛞蝓、巨人恐蚁:旅客入境行李箱藏85只外来异宠被查
今日科普10月24日消息,最抽象的行李箱诞生了,来自一入境旅客。据“海关发布”官方公布,近日,杭州萧山机场海关关员在对进境旅客行李物品进行监管时,经现场开箱检查,从一名旅客携带的行李箱中查获一批活体动物。经专业机构鉴定,这批活体动物为布鲁克林鬼焰锹甲、忍者蛞蝓、巨人恐蚁等外来“异宠”27种、共85只。目前,上述活体动物已依法扣留待后续处置。海关